24/7 IT-support: sådan minimerer I nedetid og risiko
De fleste kritiske driftsstop starter uden for kontortid: fredag aften, natten til mandag eller i en weekend. Hvis jeres IT-support kun kører 8–16, bliver fejlen ofte først set, når brugerne ringer mandag morgen. Med proaktiv 24/7 IT-support kan I fange hændelser tidligt, isolere dem og holde forretningen kørende. Det er det, der flytter nedetid fra “krise” til “ticket”.
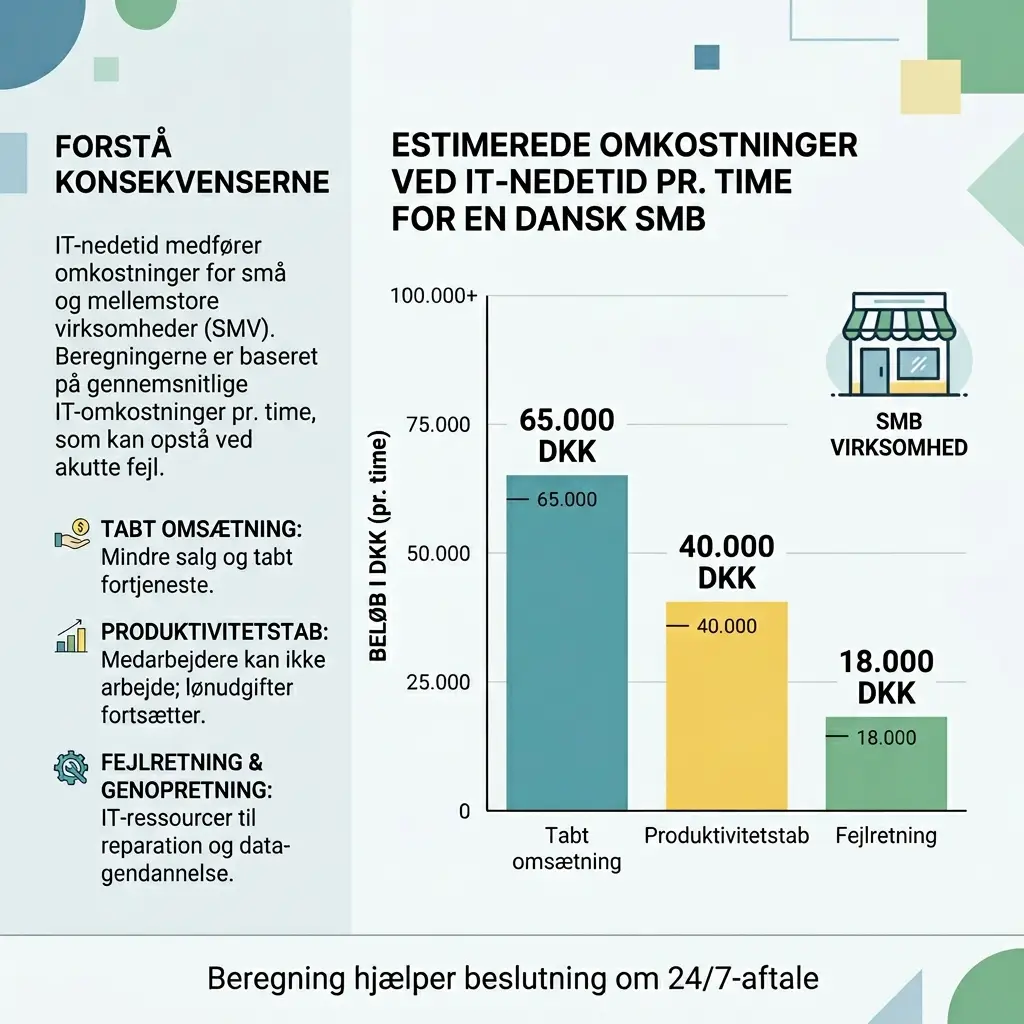
- Sæt pris på nedetid: Brug et enkelt CFO-regnestykke (tabt omsætning + løn + fejlretning) og sammenlign med en 24/7 aftale.
- Skeln mellem vagttelefon og proaktiv drift: Kræv monitorering, alarmer og automatiske playbooks – ikke kun “ring, når det brænder”.
- Gør NIS2 håndterbar: Et 24/7 IT-beredskab gør det realistisk at finde og dokumentere væsentlige hændelser inden for 24 timer (ENISA, 2024/2025).
- Reducer risikoen for ransomware uden for åbningstid: Moderne angreb kan kryptere på under 45 minutter (Microsoft, 2025) – I skal kunne reagere med det samme.
- Fjern single point of failure: Aflast intern IT og stop “uofficiel døgnvagt” med klare SLA’er og eskalation.
Hvorfor 24/7 IT-support er en økonomisk beslutning (ikke en luksus)
Hvis I vil minimere nedetid, skal I først kunne prissætte den. Datto/Kaseya peger på, at en time nedetid i gennemsnit koster en SMB ca. $8.000 (omkring 55.000 DKK) (Datto/Kaseya, 2024/2025). Sherweb angiver et spænd på $127–$427 pr. minut for SMB’er (Sherweb, 2026). Tallene varierer, men pointen er stabil: én enkelt hændelse kan betale mange måneders proaktiv overvågning.
Et CFO-regnestykke I kan bruge i ledelsen
Lav et “worst credible scenario” og et “typisk scenario”. Brug samme formel:
Pris på IT nedetid pr. time = (tabt bruttoavance pr. time) + (løn til medarbejdere, der ikke kan arbejde) + (ekstra omkostninger til fejlretning, overtid, leverandører) + (evt. bøder/kontraktbrud)
- Tabt omsætning: Hvad koster en time, hvor ordreflow, produktion eller kundeservice står stille?
- Tabt produktivitet: Antal berørte medarbejdere × gennemsnitlig timeomkostning.
- Fejlretning: Hvor mange timer går med root cause, restore, reimaging og efterkontrol?
Beslutningsregel: Hvis jeres “typiske scenario” overstiger prisen for 24/7 IT-support på et kvartal, er casen ofte enkel.
Hvordan vælger I mellem IT vagttelefon og proaktiv 24/7 overvågning?
“IT-support døgnet rundt” kan betyde to meget forskellige ting:
- Vagttelefon (reaktiv): I opdager fejlen (eller brugerne gør), og I ringer. Skaden er allerede sket.
- Proaktiv 24/7: Platformen opdager afvigelser, alarmer går til NOC/SOC, og der handles efter playbooks, før brugerne mærker det.
Før → Efter #1
Før: “Serveren er nede” opdages kl. 07:45, og I starter fejlsøgning kl. 08:15.
Efter: Overvågning ser diskfejl kl. 02:12, workload flyttes/isoleres, og brugerne møder ind til normal drift.
Før → Efter #2
Før: Patches installeres ad hoc, og en weekendopdatering giver nedbrud mandag morgen.
Efter: Patching styres, testes og rulles ud i ringe med rollback-plan og ændringslog, så fejl fanges i kontrollerede vinduer.

Tjekliste: 10 krav I skal stille til 24/7 IT helpdesk 24/7 og driftspartner
Brug tjeklisten som “minimumskrav” i jeres næste SLA aftale IT. Svarene skal kunne dokumenteres, ikke bare forklares.
- Hvad overvåges 24/7? Microsoft 365 (sign-ins, mailflow), Azure workloads, netværk, endpoints, backup jobs, certifikater, udløb af licenser/keys.
- Hvilke alarmer udløser handling? Kræv konkrete tærskler (fx mislykkede login-bølger, usædvanlig datamængde ud, backup-fejl 2 gange i træk).
- Hvad er jeres responstid vs. løsningstid? Responstid uden “time-to-mitigate” hjælper ikke. Kræv tid til inddæmning (fx isolation af konto/enhed).
- Hvem gør hvad, når alarmen går? NOC/SOC rollefordeling, eskalation til jer, og hvornår ledelsen informeres.
- Hvordan håndterer I ransomware? Playbook for: isolér endpoint, disable konto i Entra ID, stop lateral movement, verifikér backup, start restore.
- Hvordan dokumenterer I hændelser til NIS2? Logkilder, tidslinje, bevismateriale, og hvem der skriver “early warning” inden for 24 timer (ENISA, 2024/2025).
- Hvordan styrer I ændringer? Change-log, godkendelsesflow, og “break-glass” procedure.
- Hvordan sikrer I backup og restore? Ikke kun backup: krav om restore-test (fx månedligt) og RPO/RTO pr. system.
- Hvordan måler I drift? Månedlig rapport med top 10 alarmer, root causes, patch compliance, og forbedringsplan.
- Hvordan understøtter I co-managed IT? Adgange, ansvar, og hvordan intern IT kan overtage/medkøre uden friktion.
Prøv en simpel nedetids-beregner i jeres ledergruppe: Vælg 3 kritiske systemer (fx ERP, mail, filserver/SharePoint) og sæt en timepris på stop. Book 30 min. sparring, så hjælper vi jer med at omsætte tallene til et konkret 24/7 IT-beredskab for Microsoft 365 og Azure.
Hvorfor 8–16 support gør NIS2 svær at efterleve i praksis
NIS2 kræver tidlig rapportering af væsentlige hændelser inden for 24 timer (ENISA, 2024/2025). Det presser to ting frem:
- Detektion: I skal opdage hændelsen, ikke kun blive fortalt om den af en bruger eller en leverandør.
- Dokumentation: I skal kunne rekonstruere tidslinje, påvirkning og afhjælpning med logs.
Hvis et angreb starter fredag kl. 19, er “vi kigger på det mandag” ikke en plan. Microsoft peger på, at ransomware kan nå kryptering på under 45 minutter (Microsoft, 2025). Uden proaktiv IT overvågning får I både mere nedetid og dårligere dokumentation.
Fejl der koster nedetid uden for åbningstid (og hvordan I forebygger dem)
1) Cyberangreb og kompromitterede konti
Fokusér på hurtig inddæmning: blokér login, nulstil sessions, isolér enheder og stop mail-forwarding regler. 24/7 overvågning reducerer tiden fra kompromittering til handling – og dermed omfanget.
2) Hardware- og platformfejl
Forebyg med kapacitetsalarmer, disk/CPU/memory-tærskler, og automatiske checks af certifikatudløb og backup jobs. AlphaCIS (2026) vurderer, at 85% af nedetidshændelser kan forhindres via proaktiv overvågning og patching.
3) Menneskelige fejl og utilsigtet sletning
Ponemon (2024) peger på insider-relaterede fejl som en væsentlig kilde til kritisk nedetid. Beslutningsregel: Hvis en fejl kan ske med tre klik, skal restore kunne køres med fem klik – og være testet.

Sådan måler I ROI af at outsource IT support
Forrester (2025) beskriver, at virksomheder typisk ser positiv ROI inden for 6 måneder ved managed services, primært via sparet intern tid og undgået nedetid. Gør ROI konkret med tre linjer:
- Undgået nedetid: (forventede timer nedetid pr. kvartal før) − (efter) × jeres timepris.
- Frigjort intern tid: timer brugt på drift/brandudrykninger × intern timeomkostning.
- Reduceret risiko: værdien af hurtig inddæmning (fx færre endpoints berørt, mindre restore-scope).
Gartner (2025) angiver, at proaktiv IT-drift kan reducere omkostninger til nedetid med 60–80% sammenlignet med reaktiv “break-fix”. Brug spændet som scenarieanalyse, ikke som garanti.
Hvis I vil se, hvad der typisk indgår i en driftspakke hos os, kan I starte på vores side om IT-drift og MSP.
FAQ: 24/7 IT-support, nedetid og beredskab
Hvad koster 24/7 IT-support typisk?
Typisk afhænger prisen af antal brugere/enheder, kritiske systemer og krav til SLA. Tommelfingerregel: Start med at prissætte én times nedetid og brug den som “loft” for, hvad I vil betale for at undgå gentagelser.
Hvad er forskellen på IT-support døgnet rundt og proaktiv IT overvågning?
IT-support døgnet rundt kan være en vagttelefon. Proaktiv overvågning betyder, at systemer og logs overvåges 24/7, alarmer udløser handling, og der findes playbooks for inddæmning og restore.
Hvor hurtigt skal en leverandør reagere ved kritisk nedbrud?
Kræv både responstid og “time-to-mitigate”. En praktisk beslutningsregel: Kritiske hændelser skal kunne inddæmmes inden for 30–60 minutter, også uden for åbningstid, ellers kan omfanget eskalere unødigt (fx ved ransomware).
Hvordan hjælper 24/7 IT-support med NIS2 hændelseshåndtering?
Ved at sikre detektion, logindsamling og en dokumenteret proces. NIS2’s 24-timers “early warning” (ENISA, 2024/2025) kræver, at nogen kan identificere hændelsen og skabe en tidslinje, når den sker – ikke først næste arbejdsdag.
Kan vi nøjes med Microsoft 365’s egne alarmer?
De er et godt fundament, men de kræver bemanding, triage og handling. Beslutningsregel: Hvis ingen har ansvar for at reagere 24/7, er det ikke et beredskab – det er en inbox med alarmer.
Hvad skal stå i en SLA aftale IT for at minimere nedetid?
Som minimum: prioriteringsmodel (P1–P4), responstid, tid til inddæmning, kommunikationsplan, driftsvinduer, change management, krav til restore-test, samt månedlig rapportering på forbedringer.
Hvordan undgår vi at outsource IT support bliver “sort boks”?
Kræv adgang til dashboards, faste driftsmøder og en ændringslog, I kan revidere. Aftal, hvilke ændringer leverandøren må lave uden godkendelse, og hvilke der kræver jer med på beslutningen.
Sådan kommer I i gang på 14 dage (konkret)
- Kortlæg 5 kritiske services (fx ERP, Microsoft 365 mail, SharePoint/fil, VPN/remote, backup) og sæt ejere på hver.
- Definér RTO/RPO pr. service og beslut, hvad der må være nede – og hvor længe – før det er P1.
- Auditér jeres alarmer: Hvilke signaler har I i dag (M365, Azure, endpoint)? Hvem reagerer hvornår?
- Test én restore fra backup i kontrolleret vindue og dokumentér tiden fra “start” til “brugerne kan arbejde”.
- Udkast en incident-playbook for kompromitteret konto og ransomware: isolér, stop adgang, bevar logs, kommunikér, genskab.
- Indhent tilbud med tjeklisten ovenfor og sammenlign på dokumentation, time-to-mitigate og rapportering – ikke kun pris.